Original
Video Placeholder
videos/case_01_original.mp4
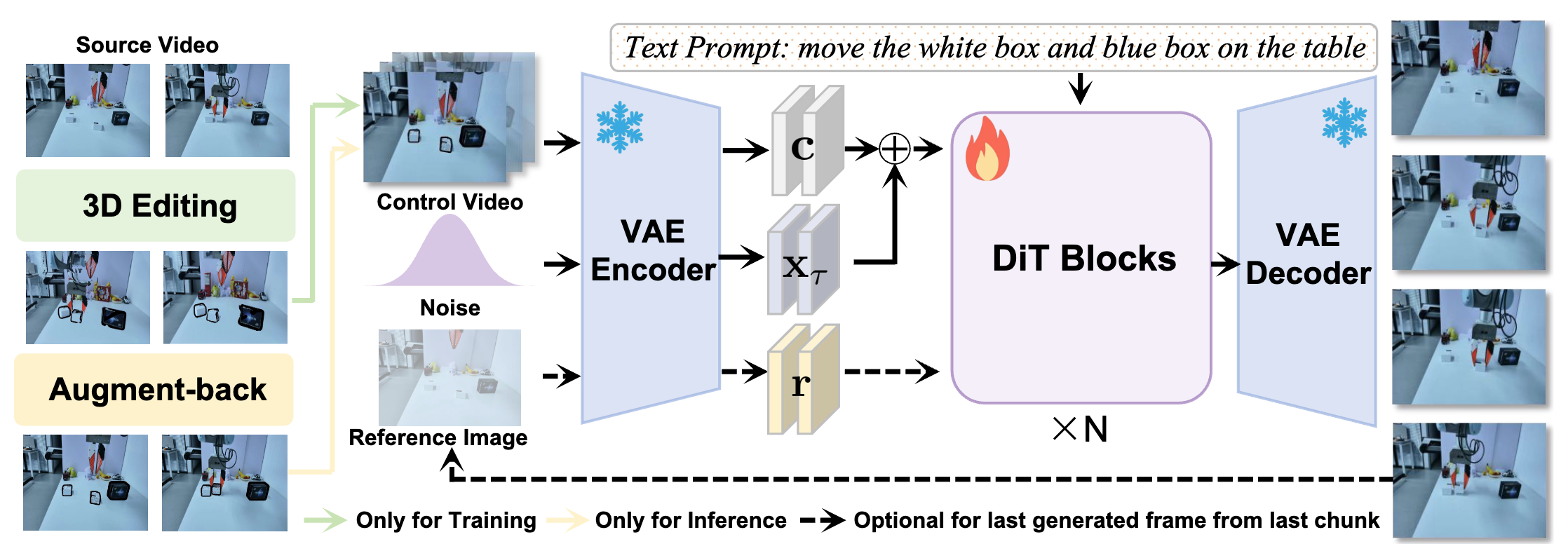
Spatial generalization is critical for imitation-learned manipulation policies, but collecting demonstrations across diverse object poses, robot configurations, and camera viewpoints is expensive. R2RDreamer is a real-to-real demonstration augmentation framework that preserves the geometric consistency of 3D action-observation editing while moving visual completion to 2D video space. It first edits incomplete object pointclouds and end-effector trajectories in a shared 3D frame, then projects the edited scene into masked image-space control videos with occlusion-aware reasoning. A dense-control image-to-video model completes temporally coherent RGB observations, producing augmented RGB-action data for compact 2D visuomotor policies and VLA-style policies.
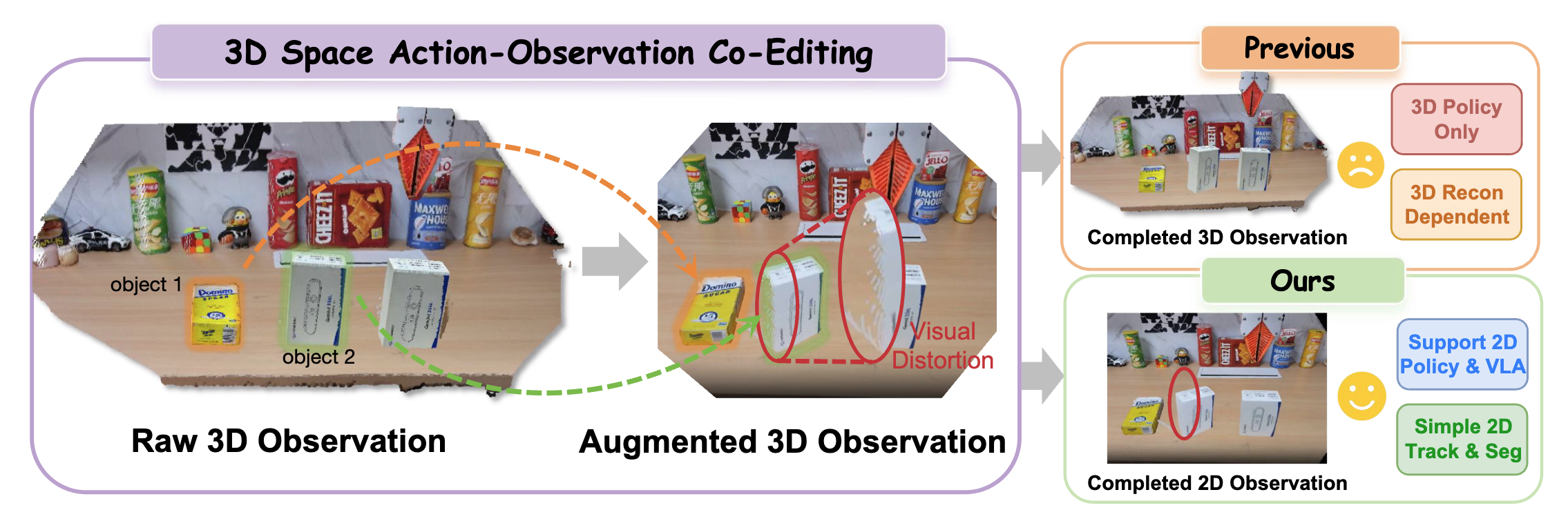
R2RDreamer keeps 3D where it is necessary for action consistency, but does not require the edited 3D scene to be a complete policy-ready observation. Incomplete geometry becomes a dense spatial control for video completion, shifting the visual-repair bottleneck from task-specific 3D reconstruction to scalable 2D video modeling.
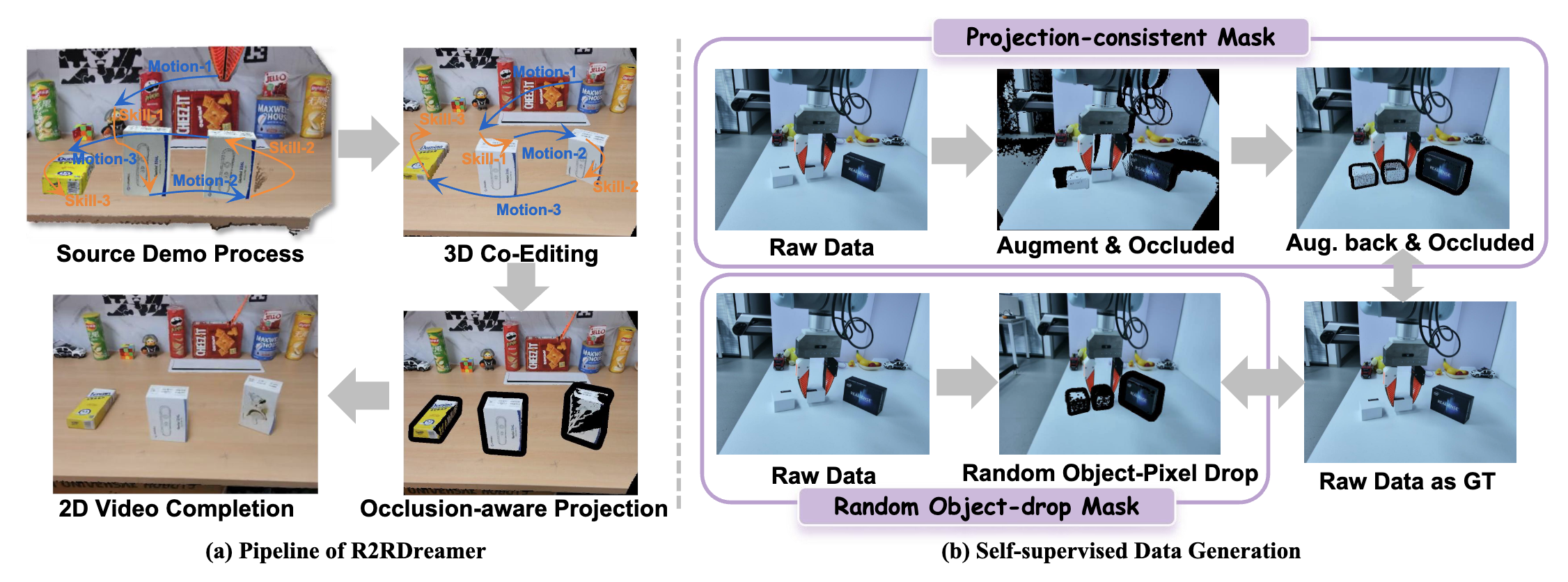
Select a case to compare the source demonstration, the edited 3D pointcloud control, and the completed augmented video.
Video Placeholder
videos/case_01_original.mp4
Video Placeholder
videos/case_01_pointcloud.mp4
Video Placeholder
videos/case_01_augmented.mp4
Video Placeholder
videos/case_02_original.mp4
Video Placeholder
videos/case_02_pointcloud.mp4
Video Placeholder
videos/case_02_augmented.mp4
Video Placeholder
videos/case_03_original.mp4
Video Placeholder
videos/case_03_pointcloud.mp4
Video Placeholder
videos/case_03_augmented.mp4
Video Placeholder
videos/case_04_original.mp4
Video Placeholder
videos/case_04_pointcloud.mp4
Video Placeholder
videos/case_04_augmented.mp4
The three videos expose the full augmentation path: the original real demonstration, the geometry-aware control produced after 3D co-editing and projection, and the completed RGB video used as policy training data.